
 Engineering
EngineeringIncident response drills
Why do incident response drills?
You don't want to be creating or testing recovery processes while things are on fire. 🔥
When things are on fire, you want to be able to focus on fixing the issues and getting your system back online and in working order as soon as possible. Having an already established incident recovery practice will allow you and your team to focus on the problem, rather than the process.
Preparing and practicing ahead of time is a good idea. Running incident response drills on an annual basis at the very least is a good idea!
How to run an incident response drill
Identify your top risks
First, create a boundary diagram if you don't already have one. You will very likely need to create a boundary diagram as part of your system's security and compliance process, anyway.
Then, review your boundary diagram and determine where your system can be accessed. Make sure that you include third party products (analytics, CI/CD pipelines, code hosting) in this analysis.
Look at each box and each connection on the diagram separately. Figure out how someone who isn't supposed to be there could get there, or how each component could fail unexpectedly.
This will help you build a set of incident scenarios to practice recovering from.
Gather organizational policies
It is likely that your Agency or OCIO has existing policies around reporting for security or data breach incidents. Gather them to ensure they are built into your response.
Create the drill
See example incident response drills for inspiration!
Invite everyone to the drill
Be sure to invite developers, infrastructure, and compliance professionals on your team to the drill. An open invitation for your team is a good idea! Letting the team know that you're doing this kind of activity builds confidence and assurance that the team takes security seriously.
Give advance warning to any third parties that might want to know that you're planning an incident response drill, such as cloud.gov or login.gov.
Schedule more time than you think you will need! If you schedule half a day, you may find you'll need the whole day!
Ask for a volunteer to take notes throughout the incident response drill.
Conduct the drill
Follow the steps in the drill, making sure good notes are taken.
Team members can rotate being the "driver" who shares their screen and walks through the steps in the drill.
Image attribution: Włodzimierz Wysocki. License: CC BY-SA 3.0
After the drill
You could end the drill with a practice "blameless post-incident retrospective." This is a low-pressure way to figure out your team's format for conducting retrospectives after an incident.
cloud.gov's retrospective meeting guide has ideas and checklists for organizing a successful post-incident retrospective.
Send an email recapping the drill to all stakeholders. Include the outcomes of the drill, what you learned from the drill, and any follow-up actions.
Example incident response drills
Scenarios worth practicing for a web app include:
- Scenario: A deploy goes wrong
- Scenario: API keys or passwords exposed
- Scenario: Compromised account
- Scenario: PII exposed
- Scenario: Oops, I deleted the database
- Scenario: Oops, I erased the S3 bucket
You don't need to drill each and every one of these scenarios each time, but they are good to plan for.
These examples are for a web application hosted on cloud.gov that generally follows our approach.
Please adjust for your infrastructure.
Scenario: A deploy goes wrong
It turns out, the new release doesn't deploy properly. It has successfully deployed in all the other environments. Let's re-deploy.
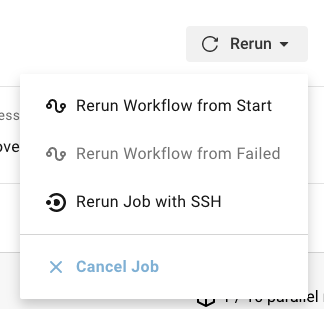
Example mitigation steps
Re-deploy last successful release from your CI/CD pipeline. (You are deploying from a CI/CD pipeline, right?)
- Go to
<<Insert CI/CD URL>>to view recent deploys. - Rerun the deploy step for the last known-good deploy.
- If necessary, roll back the database to the correct version.
<<Insert rollback steps for your application>>
Example drill
Follow the mitigation steps above in a development environment.
Scenario: API keys or passwords exposed
An API Key for an AWS service was accidentally committed to our public code repository! (Use tools like caulking to prevent issues like this from happening in the first place.)
Example mitigation steps
- Contact
<<Insert email of POC laid out in Agency policies>>and inform them of a breach. - Write down which keys and services were exposed.
- Rotate all exposed keys.
- Remove any exposed keys from the commit history.
Example drill steps
- Acknowledge that the first step would be to inform points of contact; establish that everyone knows who to inform in the event of an incident.
- To simulate the real thing, push up a file to GitHub or whichever code repository is in use with a fake service key. (No using real keys for drills, please.)
- Practice rotating the keys for that service in a development context.
- Practice scrubbing the fake key from the commit history.
Scenario: Compromised account
The website has been hacked due to a compromised key! Now instead of our link to submit a report, we have a cute image of a cat and a spam link to follow cute cats on instagram.
Photo attribution: Tran Mau Tri Tam. Unsplash License.
What happened? Was a GitHub account compromised? A cloud.gov account? A deploy key?
Example mitigation steps
- Contact
<<Insert email of POC laid out in Agency policies>>and inform them of a breach. - The first priority is to remove the unauthorized access so that there can't be further damage or information leakage. Figure out where the deploy came from.
- If the deploy was triggered from GitHub, you would be able to see it in CI/CD history. In this case, the GitHub admin should immediately remove the account that triggered the malicious deployment. Rotate any deploy credentials that may have been compromised.
- If you don't see the deploy in CI/CD, that means either deployment keys were compromised, or a cloud.gov account was compromised. Look at the logs to see which deployment method was used.
- If you see that the deploy came from a compromised cloud.gov account: Remove the compromised account from the org, all spaces (starting with prod), and all application (starting with prod apps).
- If you see that the deploy came from a compromised deploy key: In cloud.gov delete the current deployment keys, remake them and add the new keys to your CI/CD tool.
- Isolate resources: incidents that are likely to be malicious need to be handled with care to preserve forensics. The most important things to remember: do not delete an instance that has been tampered with, and do not redeploy from the last release without removing routes and renaming the instances. That could get rid of valuable forensic information. Instead:
- Remove the route to the affected instances. (This will make the bad deploy inaccessible to the public.)
- Rename the instance. (This will preserve forensics as you redeploy.)
Example drill steps
- Acknowledge that the first step would be to inform points of contact; establish that everyone knows who to inform in the event of an incident.
- Choose a scenario to drill: compromised GitHub account, compromised cloud.gov account, or compromised deploy key. (Compromised deploy key might be easiest to drill.)
- Practice the steps to remove compromised accounts or credentials, for example, by deleting the current deployment keys, remaking them, and adding them to CI/CD.
- Using a development application instance, practice removing the route to a instance that may have been compromised and then renaming it to preserve forensics.
Scenario: PII exposed
It's discovered that PII is being leaked to unauthorized users through the site.
Example mitigation steps
- Contact
<<Insert email of POC laid out in Agency policies>>and inform them of a breach. - Stop the exposure.
- Assess the severity and impact of the potential leak.
- Decide if the site needs to be set into a maintenance mode to stop further exposure. If yes, then bring up the maintenance page.
- If you are able to isolate the section of the site where the issue is occurring and remove/hide the page.
- Identify root cause of the issue and deploy a hotfix.
- Take necessary corrective action as directed by your agency security team. If there are corrective actions that the PO is able to handle in terms of contacting the affected users, do so.
Example drill steps
- Acknowledge that the first step would be to inform points of contact; establish that everyone knows who to inform in the event of an incident.
- In a development environment, practice putting the site into a maintenance mode or removing/hiding a page on the site, whichever would be most relevant to your project.
- Review any relevant corrective action / affected user notification procedures.
Scenario: Oops, I deleted the database
The database needs to be restored from a backup.
Example mitigation steps
- If you're using cloud.gov, follow cloud.gov database backup procedures.
Example drill steps
Assuming you have a staging database using a dedicated cloud.gov database plan:
- Delete some data from your staging database. (No deleting data from a production database, please.)
- Reach out to cloud.gov using the the non-emergency email address provided in thir docs; request a backup.
- Practice restoring the staging database to the point in time before you deleted the data.
Scenario: Oops, I erased the S3 bucket
Let's re-create and restore from a backup.
Example mitigation steps
- If the bucket no longer exists, create a new bucket in cloud.gov in the space where the bucket was deleted, ideally using infrastructure-as-code or a deploy script.
- Restore bucket contents from a backup.
- Verify the bucket settings, permissions, and contents are correct.
Example drill steps
Follow the mitigation steps above in a development environment.
Congratulations, you accidentally did compliance too!
For your project, you will need an ATO. Part of that ATO is providing required documentation of controls. Controls are different security considerations. This process varies from agency to agency, so, work with your security partners to know which controls they need documented. Don't forget that you can inherit a substantial number of controls by using cloud.gov and you just need to reference that it's covered. The Before You Ship guide is a great resource for ATOs.
By doing this exercise, you have artifacts (proof that you are in compliance) and documentation that you can reference or pull from for your System Security Plan. Based on the needs of your security partners and the project, you may also need additional documentation or to reference cloud.gov or AWS GovCloud's controls. The following examples are just meant as a starting point.
Contigency Planning
- CP-2 (5) Contingency plan Your troubleshooting doc is a contingency plan for your app! This document can complement existing agency contingency plans. Depending on what your security partners need, you can also make it easy to audit by naming headings like "Contingency plan," "Incident response," "Disaster Recovery," etc.
- CP-2 (7) Contingency plan: coordinate with external service providers If you did a data deletion drill in coordination with cloud.gov, you can reference that here.
- CP-3 Contingency training Your drill is training on your contingency plan. For artifacts, you can use what you wrote from your recap email and your drill document.
- CP-4 Contingency plan testing Your drill tested your contingency plan. For artifacts, you can use what you wrote from your recap email and your drill document.
Training
- AT-3(3) Role-based training: practical exercises Your drill was a practical exercise. For artifacts, you can use what you wrote from your recap email, your drill document and the practice post-incident retrospective write up.
- AT-3(5) Role-based training: processing personally identifiable information If you run your drill using the PII scenario, that would speak to this control. For artifacts, you can use what you wrote from your recap email and your drill document. The government training (those courses in OLU, for GSA) count for this as well.
Incident Response
- IR-2 Incident response training Your drill is incident response training for your application. For artifacts, you can use what you wrote from your recap email and your drill document.
- IR-3 Incident response testing Your troubleshooting drill included a security incident. You also may find a few bumps along the road as you do your drill, document those issues and any remediations you make. For artifacts, you can use what you wrote from your recap email, which should include that information.
System Inventory
- CM-8 System component inventory Use your network diagram and prep as a way to have an accurate network diagram. Keep the doc in a place that the team has access and that maintainers can edit and update it. Your network diagram and READMEs make good artifacts for this.
